


在讨论具体表类型设计之前,先明确几个贯穿所有设计的基本原则:
1. 范式与反范式的平衡:
范式化(如3NF):目的是消除冗余,保证数据一致性。适用于核心业务数据(如用户、商品)。
反范式化:
适当引入冗余,以减少关联查询,提升查询性能。适用于那些几乎不太变更的字段,否则会造成写入失控。
适当使用json串合并多个字段存储:
适用场景:
动态属性:商品的不同品类有完全不同的属性(如手机的“CPU”、书籍的“ISBN”)。主表存通用信息,JSON字段存动态属性。
配置信息:存储用户的自定义设置、系统的动态配置。
API请求/响应日志:完整记录请求体和响应体,结构可能经常变化。
轻度关联的数据:如一篇文章的“点赞用户ID列表”,查询时不需要关联user表,只在程序内解析使用。
不适用场景:
需要作为查询条件(WHERE)或需要索引的字段。虽然MySQL支持对JSON字段建函数索引,但性能和维护性不如原生字段。
需要参与关联查询(JOIN)的数据。
数据需要频繁更新其中某个特定键。更新整个JSON列的效率较低。
数据具有稳定、明确的Schema。这种情况应优先使用规范化的表结构。
2. 读写权衡:根据表的读写比例(如 读:写 = 9:1 还是 1:9)来决定是优化查询还是优化写入。
3. 数据生命周期:明确数据的“热度”(热数据、温数据、冷数据),并制定相应的存储、归档和清理策略。举个例子:①对于数据量大的表,业务上经常要使用的数据,放在在线业务库的业务表;②而用的不那么频繁,但是业务上还是会有些场景使用,比如说,一段时间内的数据有可能重新拉回到在线业务表,这种可以存储到在线业务库的历史表;③如果是很久的数据,业务上只是做查询使用或者不要求快速拉回的,则可存放在大数据的存储查询介质,如drios;④而对于业务上已不再需要使用的数据,则可归档到数仓。
4. 业务驱动:一切设计都要回归业务需求。为什么这么设计?是为了满足哪个业务场景?未来它会不会有其他的扩展可能?
5. 拆分合并原则:
单一职责原则
合:当多个字段描述的是同一个实体的不同方面,且访问模式(指的是查询频率,更新频率等)相似时;
拆:当字段属于不同的业务概念,或访问模式差异很大时;
6. 设计模板:我们一开始就要对数据模型设计有明确的模板,让研发能明确知道他们应该在表设计的时候考虑哪些点,下面就是一个我在公司推行的一个模板:
二、确认业务表之间的关系
关系分为一对一、多对一、一对多、多对多、继承;
1、一对一关系
一个大量属性的业务实体,根据更新访问频率、后期扩展性、大字段等划分成多个表;
例如根据更新访问频率划分客户基本信息及客户扩展信息。文章实体因为文章内容是大字段,划分为文章基础信息和文章内容信息。这些方法,能有效避免数据页频繁分裂,对查询,插入性能,规避binlog延迟都有很大的用处;
一个申请审批流程,业务刚开始只需要一轮审批,那申请和审批是一对一的,但是为了兼容后续有多轮审批需求,将申请信息和审批信息拆成2个表;
2、多对一关系
多对一关系在数据库设计上比较简单,在下面案例中,一个过错行为对应一个税务人员、一个纳税人与一个过错类型;同时,一个税务人员,或纳税人,或过错类型,都可以对应多个过错行为。它们就形成了“多对一”关系。多对一关系一般都是在“多”对应的表增加关联字段;
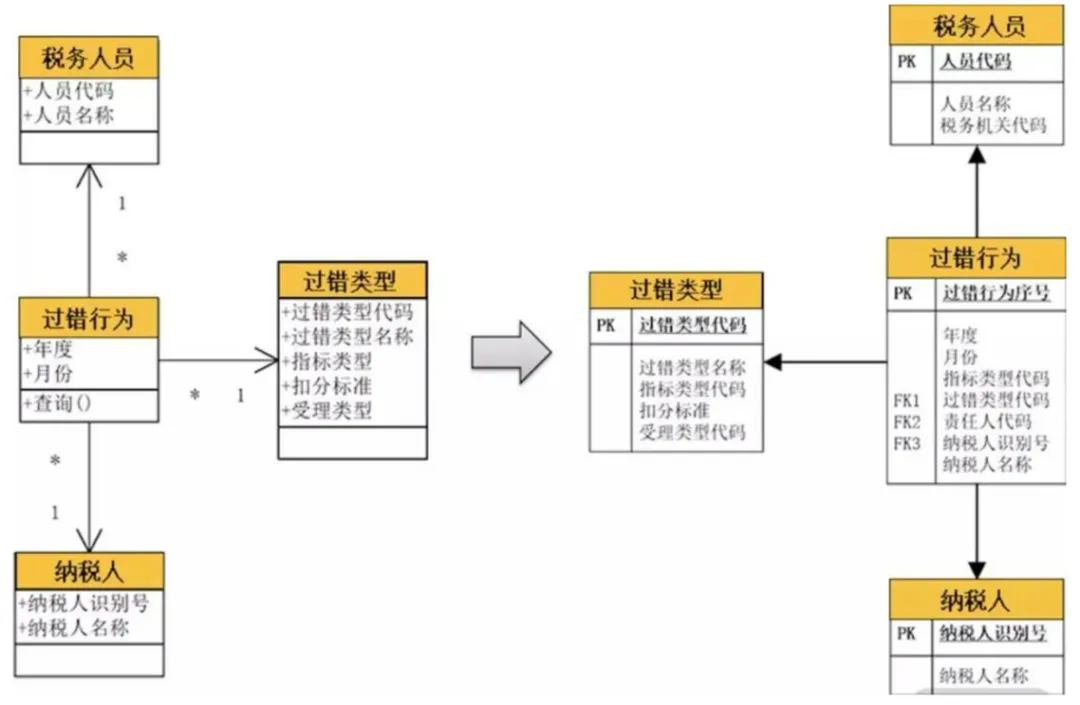
3、一对多关系
譬如,下边案例中的“申辩申请单”与“申辩申请单明细”就是“一对多”关系。除此之外,订单与订单明细、表单与表单明细,都是一对多关系。一对多关系在数据库设计上比较简单,就是在子表中增加一个外键去引用主表中的主键;
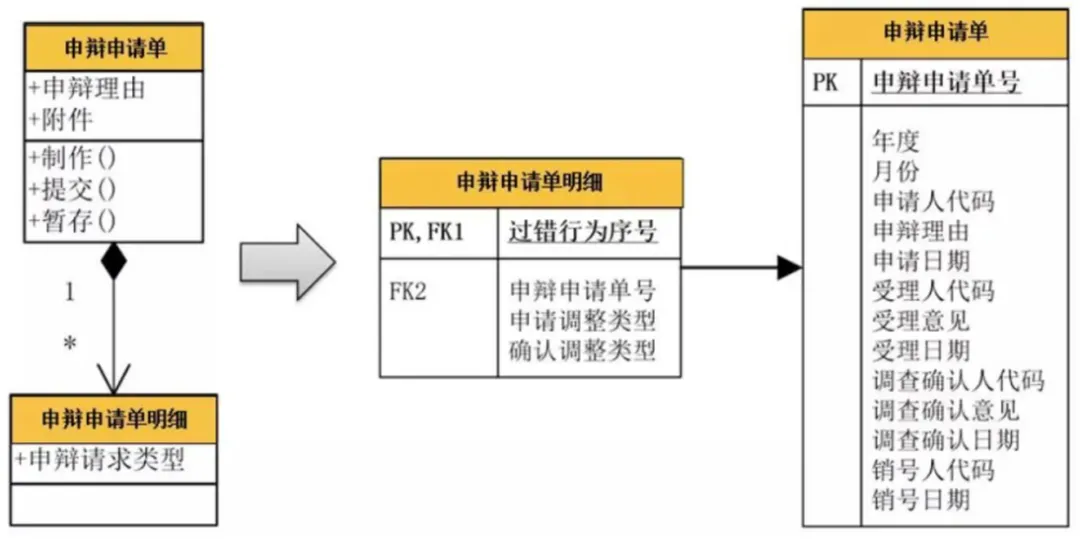
4、多对多关系
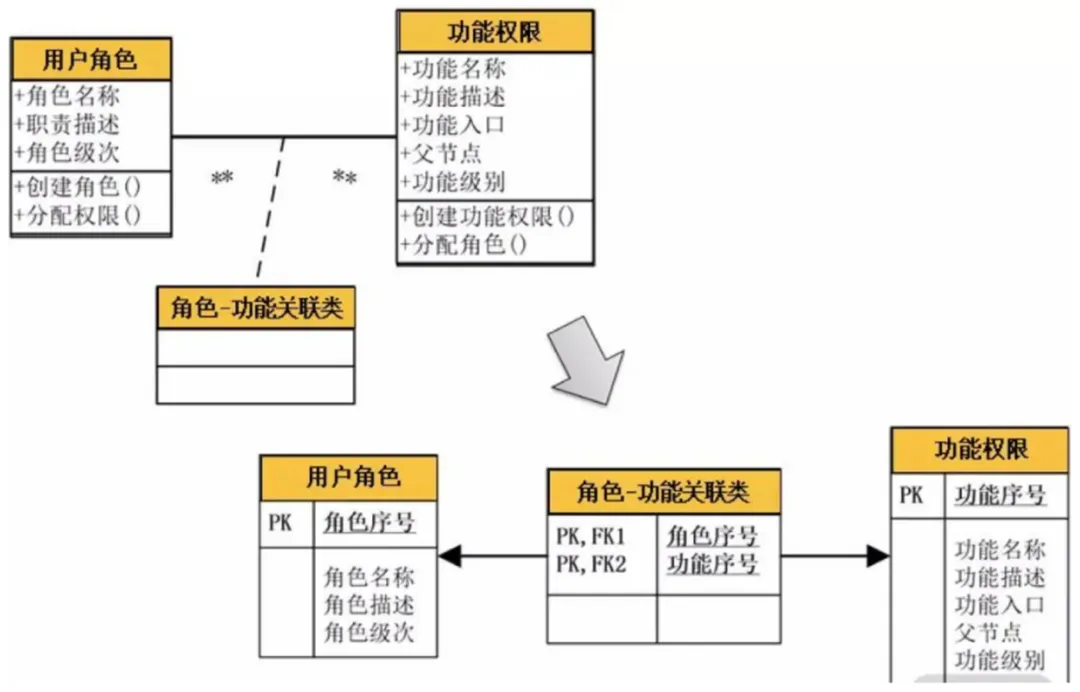
比较典型的例子就是“用户角色”与“功能权限”。一个“用户角色”可以申请多个“功能权限”;而一个“功能权限”又可以分配给多个“用户角色”使用,这样就形成了一个“多对多”关系。这种多对多关系在对象设计时,可以通过一个“功能-角色关联类”来详细描述。因此,在数据库设计时就可以添加一个“角色功能关联表”,而该表的主键就是关系双方的主键进行的组合,形成的联合主键;
5、继承关系
方案一:见下面案例。“执法行为”通过继承分为“正确行为”和“过错行为”。如果这种继承关系的子类不多(一般就2 ~ 3 个),并且每个子类的个性化字段也不多(3 个以内)的话,则可以使用一个表来记录整个继承关系。在这个表的中间有一个标识字段,标识表中的每条记录到底是哪个子类或者哪个场景,哪个类型;
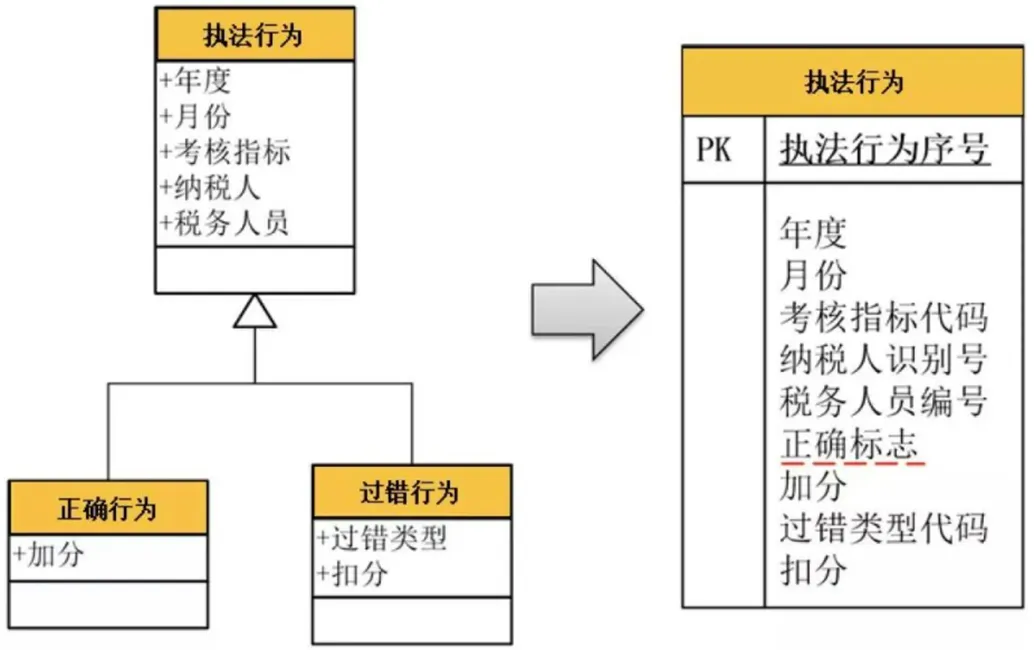
采用这个方案的优点是简单,整个继承关系的数据全部都保存在这个表里。但是,它会造成“表稀疏”。在该案例中,如果是一条“正确行为”的记录,则字段“过错类型”与“扣分”永远为空;如果是一条“过错行为”的记录,则字段“加分”永远为空。假如这个继承关系中各子类的个性化字段很多,就会造成该表中出现大量字段为空,称为“表稀疏”。在关系型数据库中,为空的字段是要占用空间的。因此,这种“表稀疏”既会浪费大量存储空间,又会影响查询速度,是需要极力避免的。所以,当子类比较多,或者子类个性化字段多的情况是不适合该方案的;
方案二:如果执法行为按照考核指标的类型进行继承,分为“考核指标1”“考核指标2”“考核指标3”……。并且每个子类都有很多的个性化字段,则采用前面那个方案就不合适了。这时候我们可以将每个子类都对应到一个表,有几个子类就有几个表,这些表共用一个主键,即这几个表的主键生成器是一个,某个主键值只能存在于某一个表中,不能存在于多个表中。每个表的前面是父类的字段,后面罗列各个子类的字段,如图所示;
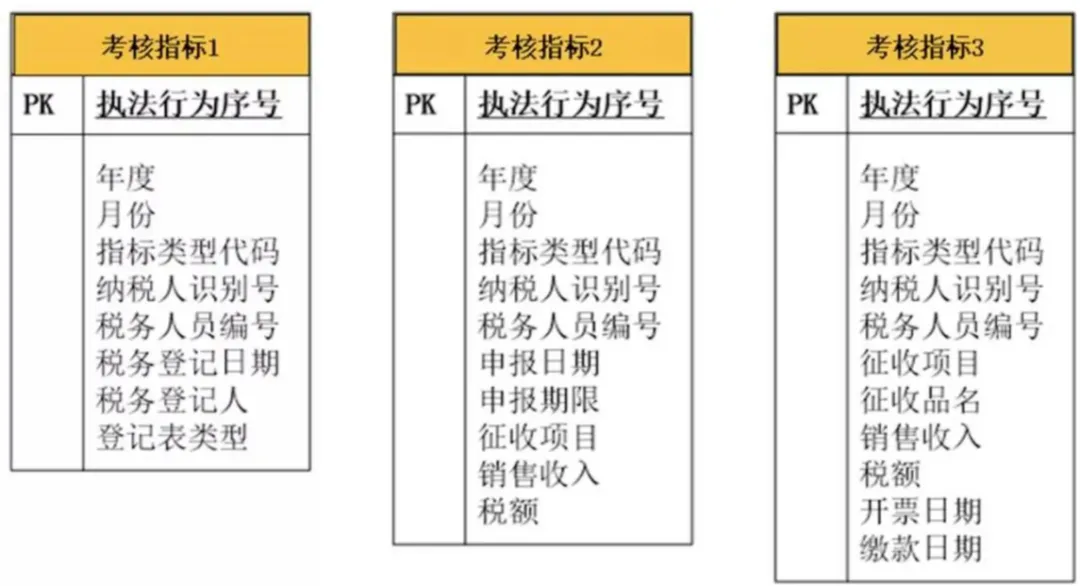
如果业务需求是在前端查询时,每次只能查询某一个指标,那么采用这种方案就能将每次查询落到某一个表中,方案就最合适。但如果业务需求是要查询某个过错责任人涉及的所有指标,则采用这种方案就必须要在所有的表中进行扫描,那么查询效率就比较低,并不适用。当然我们有时候是可以让业务妥协,查询时让指标类型成为一个必选项;
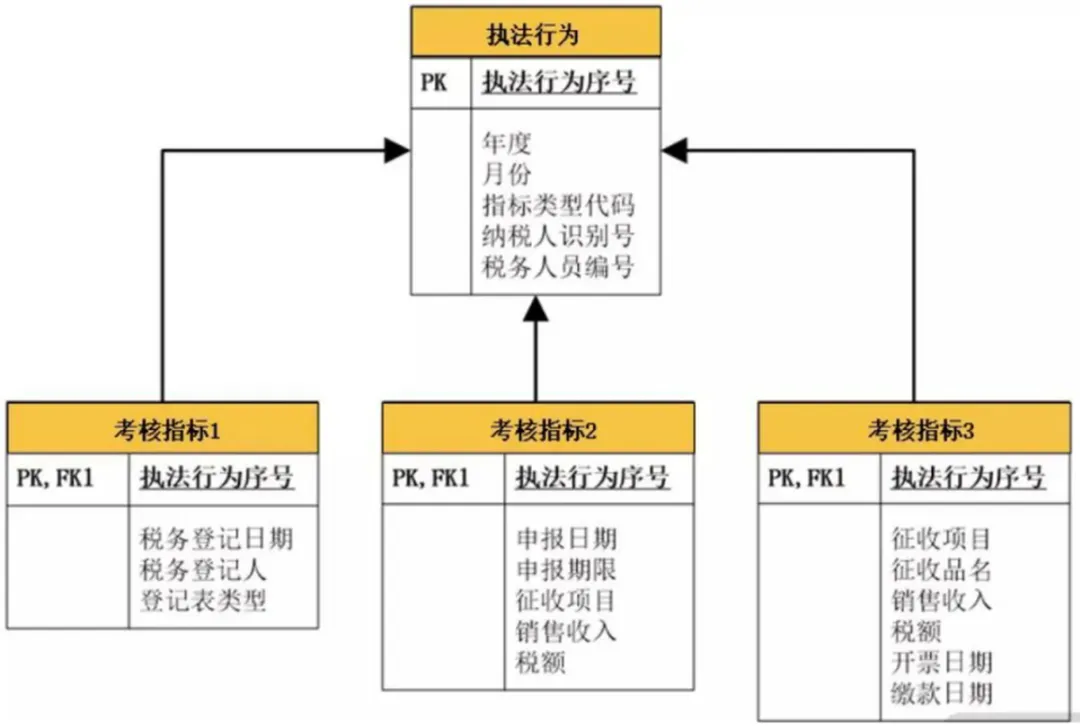
方案三:如果业务需求是要查询某个过错责任人涉及的所有指标,则更适合采用以下方案,将父类做成一个表,各个子类分别对应各自的表(如图所示)。这样,当需要查询某个过错责任人涉及的所有指标时,只需要查询父类的表就可以了。如果要查看某条记录的详细信息,再根据主键与类型字段,查询相应子类的个性化字段。这样,这种方案就可以完美实现该业务需求;
三、表分类及设计原则、使用场景
设计原则:将一组离散但相关的操作抽象为一个逻辑单元,并记录这个单元的元信息(状态、时间、操作人)。核心是 “管控” 和 “溯源”。
使用场景:
批量任务:如批量导入用户、批量生成优惠券、批量发货。需要跟踪整个批量操作的成功与否。
对账与结算:金融场景中,每日的结算跑批会生成一个结算批次,记录结算的日期、范围和状态。
数据同步或ETL:记录每次数据同步的批次,如果同步失败,可以追溯到是哪一批次的数据出了问题。
示例:

这两者非常相似,都强调 “记录事实”,一旦生成,绝不允许修改(Update)。它们的区别在于:
日志表:更偏向于 “记录系统行为”,如操作日志、系统错误日志、API调用日志。
流水表:更偏向于 “记录业务状态的变化”,是核心业务的一部分,如账户交易流水、订单状态流水。
设计原则:
只追加,不修改。
通常没有唯一主键,或主键是自增ID,与业务无关。
对查询性能要求高,通常需要按时间范围进行查询。
数据量巨大,必须有归档和清理策略。
使用场景:
操作日志表:记录用户(或管理员)的关键操作,用于安全审计。(操作人、操作时间、操作类型、IP、请求参数、结果)
交易流水表:记录每一笔资金的进出。(流水号、账户ID、交易类型、金额、交易前余额、交易后余额、对手方信息、时间)。这是对账的黄金标准。
订单状态流水表:记录订单从创建、付款、发货到收货的每一个状态变化节点和时间。(订单ID、前状态、新状态、操作人/系统、时间)。用于追踪订单生命周期。
示例(交易流水):

设计原则:处理 “缓慢变化维(SCD)” 问题,高效存储历史快照。它记录一个事实在生命周期内,各个时间段的状态。核心字段是start_date和end_date。
使用场景:
会员等级变化:需要查询用户在某个历史时间点(例如去年双十一)的等级。
员工部门调动:需要统计某个员工在任意时间段内在哪个部门。
商品价格变化:需要分析某个商品在促销期间的价格。
设计要点:
start_date:该记录生命周期的开始。
end_date:该记录生命周期的结束。通常用一个极大的值(如9999-12-31)代表当前有效记录。
当数据发生变化时,不是修改原记录,而是关闭旧记录(更新其end_date),并插入一条新的当前有效记录。

设计原则:存储系统运行所需的静态配置数据、枚举值和业务字典,实现配置与代码分离。
使用场景:
系统参数配置:如超时时间、重试次数、开关配置等
业务字典:订单状态、支付方式、国家地区代码等
枚举值存储:性别、用户类型、优先级等
前端下拉选项:分类选项、标签选项等
示例:

设计原则:预计算和存储聚合结果,用空间换时间,提升复杂统计查询性能。
使用场景:
Dashboard数据:实时展示的运营数据、KPI指标
报表系统:日/月/年统计报表
排行榜:用户积分榜、商品销量榜
缓存复杂查询结果:需要多表关联和复杂计算的统计结果
示例:

设计原则:基于数据库实现简单的消息队列或任务调度,保证任务的可持久化和重试。
使用场景:
异步任务处理:发送邮件、短信、推送通知
分布式任务调度:定时批处理任务
工作流引擎:流程审批、状态机流转
数据同步:跨系统数据同步任务
示例:

设计原则:存储核心数据的版本历史,支持数据追溯和版本回滚。
使用场景:
合同/协议版本:存储每次修改的完整版本
配置变更历史:系统配置的每次变更记录
文档版本管理:Wiki、知识库的版本控制
审核流程:存储每次审核的完整快照
示例:

设计原则:存储和查询地理空间数据,支持位置相关业务。
使用场景:
地理位置服务:门店位置、配送范围
区域划分:行政区域、商圈划分
距离计算:附近的人、附近的商家
地理围栏:电子围栏、区域监控
示例:

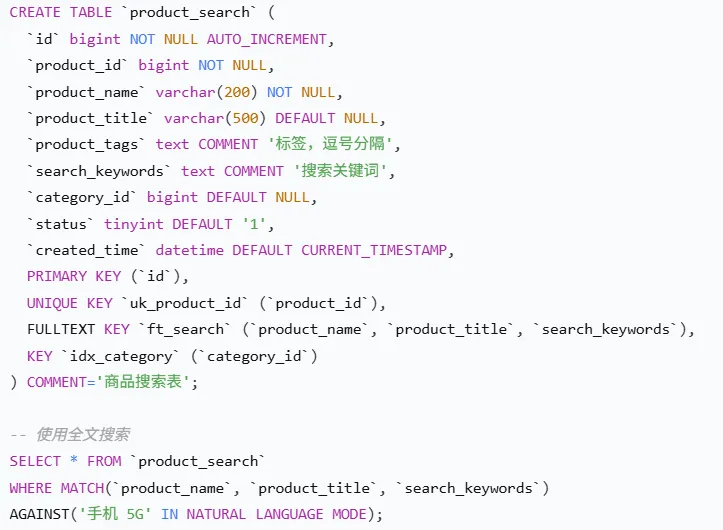
设计原则:优化文本搜索性能,支持复杂的搜索需求。
使用场景:
搜索引擎:商品搜索、内容搜索
标签搜索:多标签组合查询
模糊匹配:名称、描述的模糊查询

使用场景:
动态属性系统
电商平台中不同品类的商品有完全不同属性
CRM系统中客户自定义字段
配置管理系统
标签,变量等;
稀疏数据存储
大多数实体只有少数几个属性有值
避免传统表中大量NULL字段
元数据驱动系统
需要运行时动态添加字段
多租户SaaS应用中不同租户需要不同字段
随着数据库发展,目前MYSQL8.0已经很好的支持了JSON数据类型,现在更推荐使用 JSON字段 作为 EAV 的替代:

适用场景:
标签是动态的,可能经常变化。
标签的结构不一致,不同用户可能有不同的标签集合。
不需要对标签进行复杂的关联查询(如多表连接),而是通过用户ID直接获取所有标签。
读取频率远高于更新频率。
不适用场景:
需要频繁地对单个标签进行增删改(因为更新整个JSON字段成本较高)。
需要根据标签值进行复杂的查询(如范围查询、多条件组合查询等)。
需要跨用户对标签进行聚合查询(如统计拥有某个标签的用户数量)。
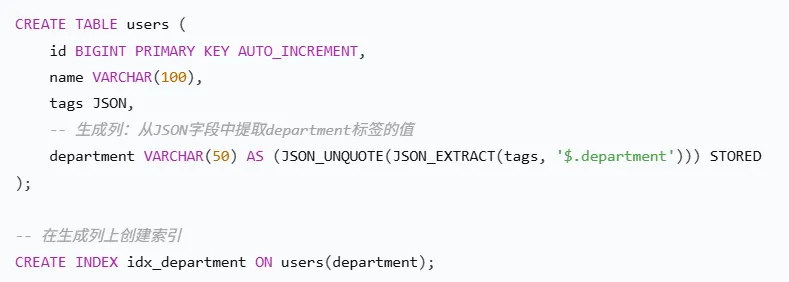
使用JSON索引:如果你需要根据某个特定的标签键值对进行查询,可以考虑使用生成列(Generated Column)并在其上创建索引。
例如,假设我们有一个users表,其中有一个tags的JSON字段,我们想根据标签department的值来查询用户。


使用场景:
多状态标志存储
用户权限系统
功能开关配置
标签系统
高效集合运算
用户分群(具有某些特征的用户集合)
商品标签筛选
实时统计计数
在线用户统计
实时数据分析
示例:


设计原则:高效存储和查询层次结构数据。
常用四种设计模式:
①邻接表模式:

结构:每个节点存储其父节点的ID。
推荐使用场景:
深度固定的浅层树
组织架构(公司-部门-小组)
评论系统(通常限制2-3级回复)
菜单导航(通常3-4级深度)
频繁的增删改操作
需要经常添加、删除、移动节点
业务变动频繁的树形结构
简单父子关系查询
主要查询直接父节点或直接子节点
不需要复杂的层级遍历
不适用场景:
需要查询所有子孙节点
需要查询完整路径
树的深度很大且需要高效查询

结构:每个节点存储从根节点到当前节点的路径(如用字符串存储像'/1/2/3'这样的路径)。
推荐使用场景:
频繁的路径查询
需要快速获取节点的完整路径
面包屑导航、位置显示
固定深度的分类系统
商品分类(如: 家电/大家电/空调)
文章分类、文件目录
基于路径的权限控制
需要根据路径模式进行权限验证
数据库不支持递归查询的环境
老版本MySQL等
不适用场景:
树结构频繁变动(移动节点成本高)
路径长度可能很长(受限于字段长度)
需要频繁查询所有子孙节点

结构:使用一个额外的表来存储节点之间的关系,包括直接和间接的父子关系,每条记录存储祖先节点和后代节点以及它们之间的深度(可选)。
推荐使用场景:
复杂的层级关系查询
需要频繁查询任意深度的子孙节点
需要频繁查询任意深度的祖先节点
需要计算节点间的距离
树结构稳定,查询频繁
权限菜单系统
知识库分类
地区行政区划
需要高性能的树遍历
对查询性能要求极高的场景
不适用场景:
树结构频繁变动(维护成本高)
数据量极大(关系表会快速增长)
简单的父子关系查询(杀鸡用牛刀)


四、数据模型设计的一些高阶规范
尽可能小:在满足业务需求的情况下,选择尽可能小的数据类型。例如,如果年龄范围在0-200,使用TINYINT UNSIGNED(0-255)而不是INT。
避免使用NULL:除非必要,否则将字段设置为NOT NULL。因为NULL值会使索引、索引统计和值比较都更复杂。如果业务上允许,可以使用默认值(如空字符串、0等)代替NULL。
字符串类型:
固定长度使用CHAR,可变长度使用VARCHAR。
VARCHAR长度不要超过实际需要,避免过度分配。
对于大量文本,使用TEXT类型,并考虑与主表分离(避免影响主表查询性能)。
数值类型:
整数类型:TINYINT、SMALLINT、MEDIUMINT、INT、BIGINT,根据范围选择。
小数类型:DECIMAL用于精确计算(如金额),FLOAT和DOUBLE用于近似计算。
时间类型:
DATE、TIME、DATETIME、TIMESTAMP。注意TIMESTAMP的范围(1970-2038)和时区问题。
通常推荐使用DATETIME(范围更大)或TIMESTAMP(自动时区转换,但注意范围)。
主键最好是单列、简单(如整数类型)且不变(不使用可能会改变的列,如姓名)。
推荐使用自增主键(AUTO_INCREMENT)或业务无关的唯一标识(如UUID,但注意UUID的存储和索引性能问题)。
如果使用自增主键,注意在分布式环境下可能使用雪花算法等生成唯一ID。
将TEXT、BLOB等大字段单独存放到扩展表中,避免在查询主表时由于大字段导致性能下降。
1.4 关联字段统一
表之间关联的字段需要保证数据类型,长度,排序规则(这个在表级别统一设置即可,不要在每个字段指定)都一致。
索引不是越多越好,每个索引都会降低写操作(INSERT、UPDATE、DELETE)的速度。
为查询条件(WHERE)、连接条件(JOIN)、排序(ORDER BY)和分组(GROUP BY)的列创建索引。
主键索引:每张表都必须有主键索引。
唯一索引:保证数据唯一性,如手机号、邮箱等。
普通索引:加速查询。
复合索引:注意索引列的顺序,遵循最左前缀原则。
覆盖索引:索引包含查询所需的所有字段,避免回表。
将选择性高的列放在前面(选择性=不重复的值数量/总记录数)。
考虑查询条件的使用频率和顺序。
避免创建重复索引,如已有索引(a,b),再创建索引(a)就是多余的。
2.4 唯一索引设计
可根据业务需要,适当建单字段唯一索引,且单字段是全局整体增长的,如订单号,序列号,流水号。能不建就不建,在应用程序层保证数据不重复。
尽量避免建复合唯一索引和多个唯一索引,即使事务级别是RC,理论上基本都是加行锁,但是多字段联合的唯一索引,在批量插入的场景下,“唯一索引冲突检测”,会让你在 RC 级别“意外”碰到间隙锁/Next-Key Lock。因为每次多线程并行批量插入,多字段组成的唯一键,它并没有顺序性,导致互相等待间隙释放,一般数据库死锁很多都是它引起的。
不要在索引列上使用函数或表达式,会导致索引失效。
避免在索引列上使用范围查询(如<>、NOT IN、LIKE以通配符开头),这会导致索引失效。
避免在索引列上使用NULL值,如果字段可能为NULL,考虑使用默认值。
单张表索引数量建议不超过5个。
对长字符串列建立索引,可以考虑使用前缀索引(例如:INDEX (column_name(10))),但注意选择性。
统一使用UTF8MB4字符集,支持所有字符包括emoji。
排序规则根据业务选择,如utf8mb4_general_ci或utf8mb4_unicode_ci。
除非必要,否则避免使用触发器、存储过程、分区,因为不利于维护和扩展。




